スペシャルコンテンツ >> マルチ・メニーコア用語辞典
| あ | か | さ | た | な | は | ま | や | ら | わ |
|---|
た行
データ並列(Data parallelism)とプロセス並列(Process parallelism)
一般にはデータ並列と対比される概念はタスク並列(Task parallelism)と呼ばれている。 しかし、トプス・システムズなどタスク並列にあたる部分をKPN(Kahn process network)化 して考えているデータフロー派の人々は、データ並列に対するにプロセス並列と呼ぶことが多いようだ。
単純に言えば、データ並列は複数のデータに対して同じような処理をする必要があるときに、 その処理をループで回すのではなくて、複数の処理機構を並列に動かして並列に処理してしまおうという考え方である。 例えば画面を小さな部分に分割して、それぞれ別なプロセッサで処理しようなどという方式は 典型的なデータ並列の考え方の一つである。また、SIMD命令のような異なるデータに同時に同じ演算を施すのも、 粒度は小さいがデータ並列である。

当然ながら、データ並列を行う上で、隣の処理機構のデータに依存するようなデータを 処理しなければならないという部分があると、それを待つ時間が必要になるのでオーバーヘッドとなる。
これに対して、複数の処理機構をパイプのように接続し、パイプを流れるデータを次々に加工していこうとするのがプロセス並列(タスク並列)の考え方である。マイクロプロセッサ自身、フェッチ、デコード、イクゼキュート、ライトバックといったパイプライン動作をしており、この機構はもっとも細かいレベルでのプロセス並列とも言えないこともない。
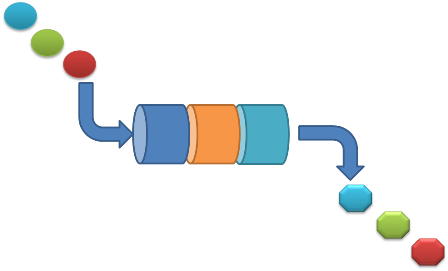
2つの概念は対比されることが多いが、共存できないわけではない。それどころか、多くのシステムでは何らかの形で併用されていることが多い。ただし、多くのマルチプロセッサシステムでは、データ並列処理側に重点がおかれる。単純にシングルプロセッサシステムでの処理を複数束ねて走らせるという処理が分かりやすく、ソフトウエアが記述しやすいためであるだろう。しかし、データ並列処理の場合、並列に実行される各処理機構に同等な処理をできるだけのハードウエアリソースを持たせねばならないということに注意しなければならない。全体処理の中でたった1箇所あらわれる重い演算といえども全ての処理機構は同等に処理できなければならないから、それを実行できねばならない。これに対して、プロセス並列処理の場合、処理機能毎に分割して考えることができるので、重い演算機構は特定の処理ステージにのみ存在すればよく、また、その処理ステージはその重い演算に専念できる。プロセス並列処理は、ソフトウエアの分割の手間がかかるものの、一般にハードウエアリソースの上では有利なことが多い。
© Copyright 2003 - 2013 TOPS Systems Corporation